
Common encoding settings
IDE/editors
Screenshot shows configuring the encoding for a single file in WebStorm.

Page source
Screenshot of the page source in Chrome.


Network requests
Screenshot of the encoding info shown for an XHR request in Chrome DevTools.



URLs

Programming languages

Why encodings exist
Inside a computer, everything is ultimately stored as the binary digits 0 and 1. Encodings define how characters are persisted and rendered.
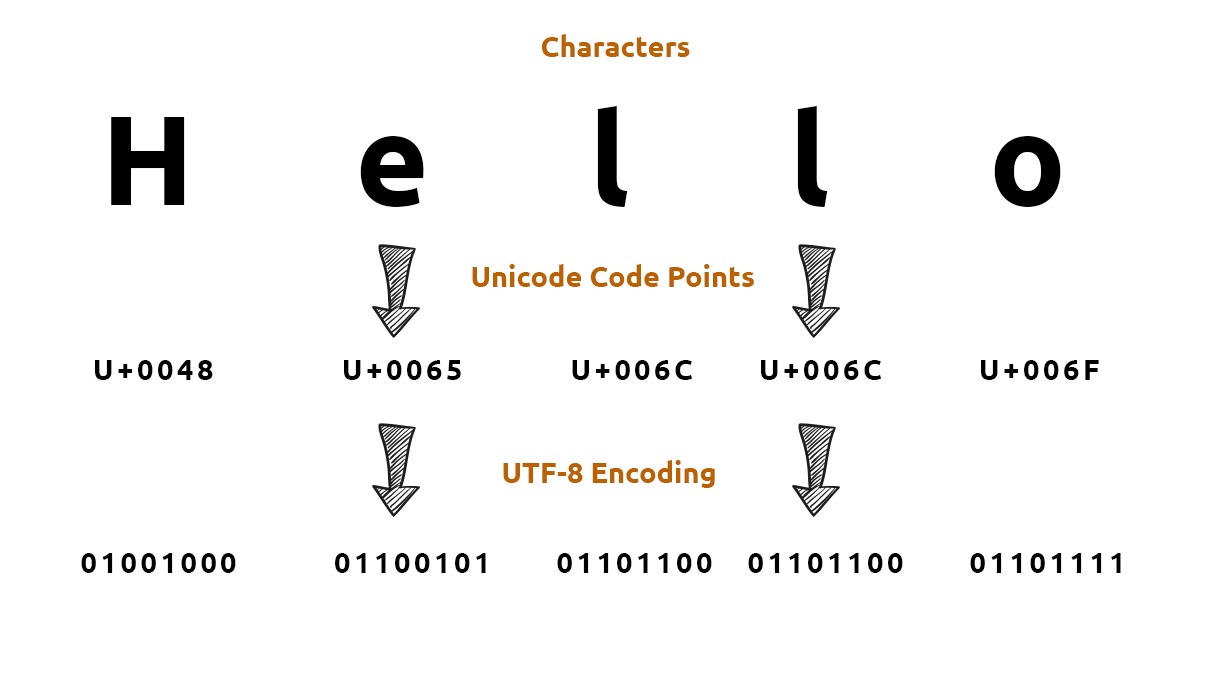
ASCII vs. Unicode vs. UTF-8
A few concepts show up frequently; it helps to separate them clearly.
ASCII is an encoding based on the Latin alphabet that represents 128 characters, so it cannot represent many languages (Chinese included).
- Those 128 characters cover
a-z,A-Z,0-9, punctuation such as+-, and some control characters such asACK.
- Those 128 characters cover
Unicode is a character set whose goal is to assign a code to every symbol in every language. For example, the Chinese character for “middle” is
U+4E2D, while the Japanese katakana character “u” isU+30A6. Every symbol maps to a unique code point. The code points themselves are fixed-width, so naïvely storing everything in Unicode would waste space. Unicode is also called Universal Coded Character Set or UCS.UTF-8/ASCII are encodings — they define how code points are stored or transmitted. UTF-8 is one implementation of Unicode. For example, that “middle” character becomes
中when encoded in UTF-8.- UTF-8 is backward compatible with ASCII.
- If Unicode is the interface, the various UTF encodings are implementations.
Timeline
- The first ASCII standard was published in 1963.
- Unicode 1.0 arrived in 1991.
- UTF-8 debuted in 1992.
Where is a file’s encoding stored?
Per the Unicode spec, a file may start with a special character called the zero-width no-break space to indicate encoding order (the BOM).
Other encodings
Base64
Characteristics:
- Any binary file can be converted into printable text so that it can be edited as plain text.
- It provides a lightweight form of obfuscation.
Aside from Base64, there is Base58. Compared with Base64, it drops characters that are easy to confuse: the digit 0, uppercase O, uppercase I, lowercase l, and the symbols + and /, i.e., 64 − 6.
URL encoding
JavaScript provides helpers such as encodeURI and encodeURIComponent for URL encoding.
Why mojibake happens
Because the encoding used to store the data doesn’t match the encoding used to read/display it.



A quick example: ISO-8859-1 is based on ASCII and adds 96 characters in the 0xA0–0xFF range for Latin languages with diacritics, but it still cannot represent Chinese characters. UTF-16 is not backward compatible with UTF-8.
Detecting encodings
https://github.com/aikuyun/iterm2-zmodem/blob/master/iterm2-recv-zmodem.sh




