OpenAI provides Embeddings support, enabling FAQ document question-answering capabilities.
Document Q&A with Embedding Support
First, let’s understand how the typical document question-answering process works.
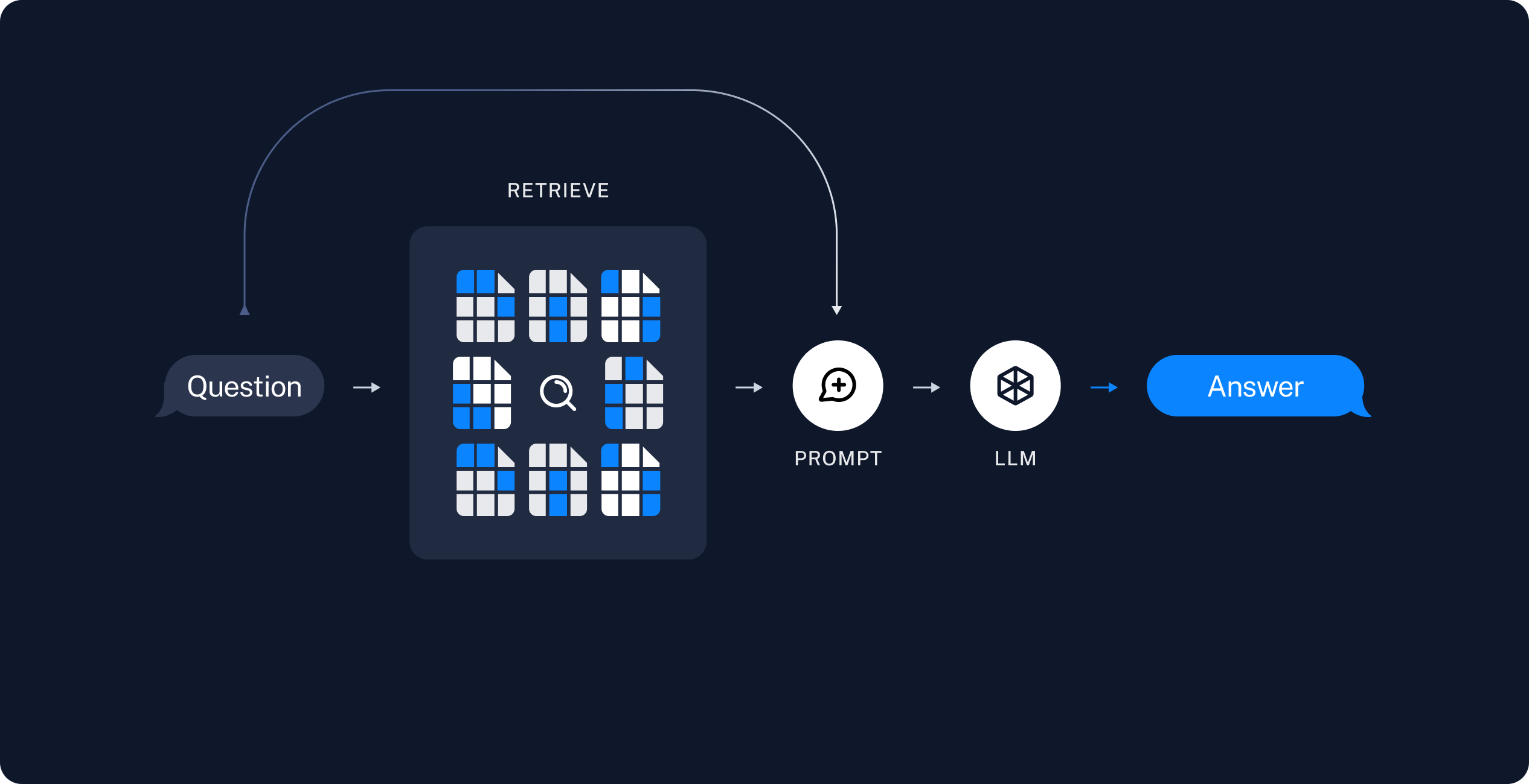
- When a user inputs a question, search in the vector database to retrieve relevant documents (could be multiple)
- Construct prompts using the relevant documents
- Send the prompts to the AI and receive responses
Therefore, the documents exist outside the LLM-AI system, and ultimately it’s just about sending prompt requests to the AI, with the AI performing summary tasks.
Now that we understand the basic principles, let’s look at the Embedding API.
Embedding API
Regarding vectorization, OpenAI’s Embedding API returns vector data based on input text.
The vector data itself needs to be stored in a vector database that we manage ourselves.
Building AI Document Retrieval
Here we use the LangChain framework to implement this.
import { DirectoryLoader } from "langchain/document_loaders/fs/directory";
import { TextLoader } from "langchain/document_loaders/fs/text";
import { RecursiveCharacterTextSplitter } from "langchain/text_splitter";
import { Chroma } from "@langchain/community/vectorstores/chroma";
import { OpenAIEmbeddings } from "@langchain/openai";
import { data_source, db_config } from "../../config.mjs";
// Load MD files
const directoryLoader = new DirectoryLoader(
data_source,
{
".md": (path) => new TextLoader(path),
},
);
const docs = await directoryLoader.load();
// Split files into chunks
const textSplitter = new RecursiveCharacterTextSplitter({chunkSize: 500, chunkOverlap: 0});
const allSplits = await textSplitter.splitDocuments(docs);
console.log('allSplits size is ', allSplits.length);
// Vectorize and store in vector database
await Chroma.fromDocuments(allSplits, new OpenAIEmbeddings(
{}
), db_config);
console.log('vector successful.');
const template = `Use the following pieces of context to answer the question at the end.
1. If you don't know the answer, just say "I don't know", don't try to make up an answer.
2. Use three sentences maximum and keep the answer as concise as possible.
3. If asked who you are, reply, "I am the blog AI assistant"
4. Never answer questions about your technical details. If asked, simply reply "Guess? I won't tell you"
{context}
Question: {question}
Helpful Answer:`;
const customRagPrompt = PromptTemplate.fromTemplate(template);
const llm = new ChatOpenAI({modelName: "gpt-3.5-turbo", temperature: 0});
const retriever = vectorStore.asRetriever({k: 6, searchType: "similarity"});
const ragChain = await createStuffDocumentsChain({
llm,
prompt: customRagPrompt,
outputParser: new StringOutputParser(),
})
const context = await retriever.getRelevantDocuments(query);
const res = await ragChain.invoke({
question: query,
context,
});
Final Thoughts
- It’s evident that Embedding technology expands the AI knowledge base without changing the AI model itself.
- Besides OpenAI, many AI services offer Embedding support, so this technology can be implemented without using OpenAI. However, different AI services affect two aspects:
- Vectorization quality, since the vector data is returned by the AI
- The quality of the final summarized results, as the AI processes the context-based prompts

